Bias, Variance, Under-fitting, and Over-fitting and bias variance tradeoff
👋 Hi there, I am Nirmal. I am a former software engineer with a keen interest in data science and analytics domains. Besides, I love to contribute to open source and help others to understand various tech stuffs.
Bias in Machine Learning
Bias refers to the simplifying assumptions made by a model to make the target function easier to learn.
High bias can lead to underfitting
Represents the error introduced by approximating a real-world problem
Example: A linear regression model trying to fit a non-linear relationship
For example: A facial recognition system trained primarily on one ethnic group may show high bias when attempting to identify individuals from other ethnicities.
Variance in Machine Learning
Variance is the amount that the estimate of the target function will change if different training data is used.
High variance can lead to overfitting
Indicates how sensitive the model is to fluctuations in the training data
Example: A decision tree with many branches, fitting noise in the training data
For example: A stock price prediction model that performs exceptionally well on historical data but fails to accurately forecast future prices due to overemphasis on past patterns.
The Underfitting Problem
Underfitting occurs when a model is too simple to capture the underlying patterns in the data.
Results in poor performance on both training and testing data
Signs include consistently poor performance and high errors
Often due to oversimplified models or insufficient feature engineering
For example: A linear model trying to predict housing prices based solely on square footage, ignoring crucial factors like location and amenities.

The Overfitting Challenge
Overfitting happens when a model learns the training data too well, including its noise and fluctuations, but fails with testing or unseen data.
Performs well on training data but poorly on new, unseen data
Characterized by high variance and complex decision boundaries
Can occur due to excessive model complexity or training on limited data
For world example: An image classification model that correctly identifies dogs in training images by memorizing specific background details (like grass) rather than learning general dog features.

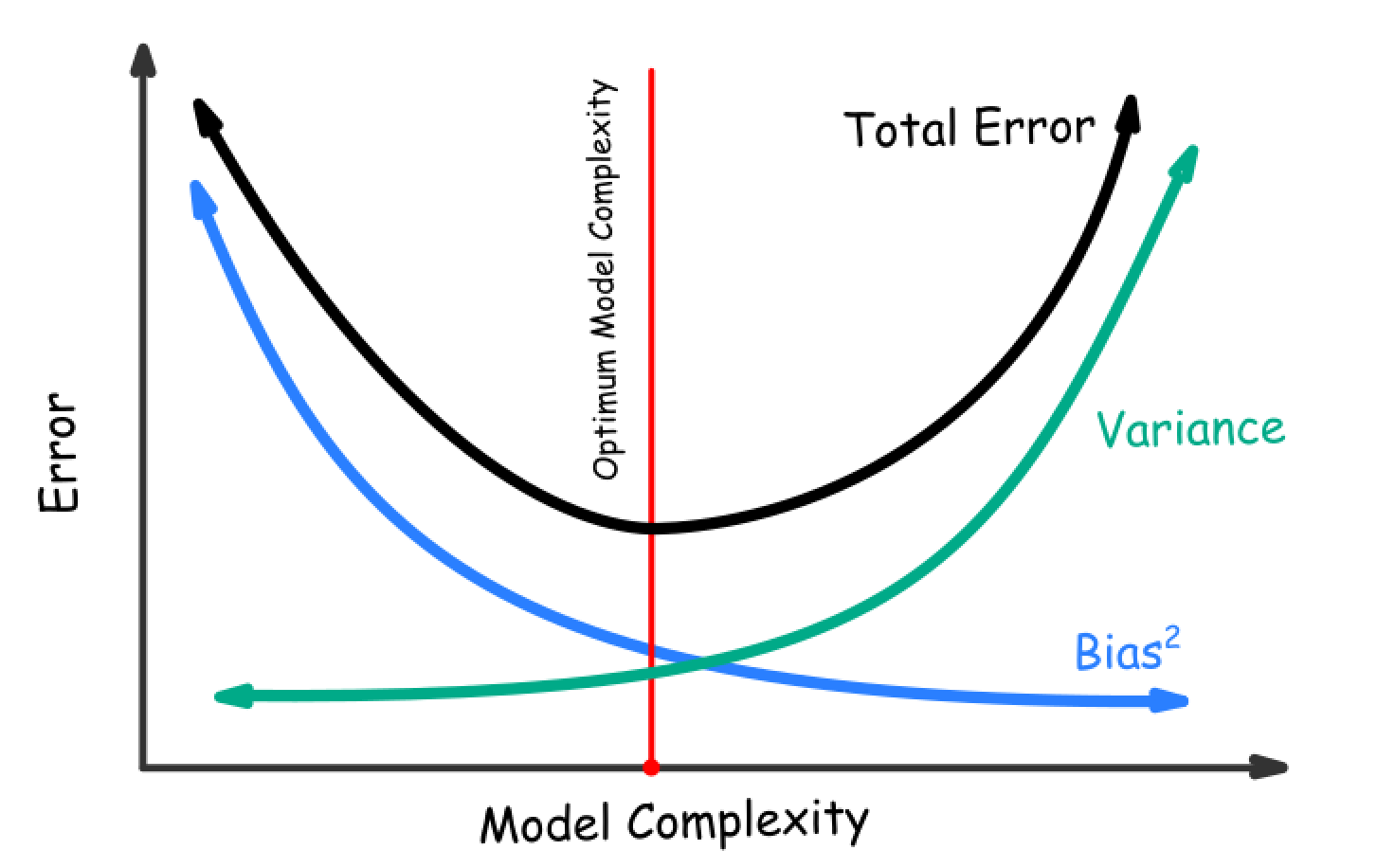
Balancing Act: The Bias-Variance Tradeoff
The bias-variance tradeoff involves finding the optimal balance between underfitting and overfitting.
Increasing model complexity generally decreases bias but increases variance
The goal is to find the sweet spot with low bias and low variance
Techniques like cross-validation and regularization help achieve this balance
Real-world example: In predicting student academic performance, finding the right set of features (e.g., past grades, study habits) without including irrelevant factors (e.g., favorite color) to create a model that generalizes well.
By understanding and managing the bias-variance tradeoff, data scientists can develop more robust and accurate machine learning models that perform well on both training and unseen data